


Распознавание текста. Бесплатная программа — аналог FineReader


- Информация о материале
- Категория: MS Office
- Опубликовано: 07.06.2020, 16:44
- Автор: HelpDesk
- Просмотров: 791

Рано или поздно, все кто часто работает с офисными программами, сталкиваются с типичной задачей — отсканировать текст с книги, журнала, газеты, просто листочков, а затем перевести эти картинки в текстовый формат, например, в документ Word.
Чтобы это сделать необходим сканер и специальная программа для распознавания текста. В этой статье пойдет речь о бесплатном аналоге FineReader — CuneiForm
1. Особенности программы CuneiForm, возможности
CuneiForm
Программа для распознавания текста с открытым исходным кодом. К тому же, работает во всех версиях Windows: XP, Vista, 7, 8, что радует. Плюс к этому добавьте полный русский перевод программы!
Плюсы:
— распознавание текста на 20 самых популярных языках мира (английский и русский само собой входит в это число);
— огромная поддержка различных печатных шрифтов;
— проверка по словарю распознанного текста;
— возможность сохранения результаты работы в нескольких вариантах;
— сохранение структуры документа;
— отличная поддержка и распознавание таблиц.
Минусы:
— не поддерживает слишком большие документы и файлы (более 400 dpi);
— не поддерживает на прямую некоторые типы сканеров (ну это не страшно, в комплект к драйверам сканера идет и спец. программа для сканирования);
— дизайн не блещет (но кому он нужен, если программа в полной мере решит задачу).
2. Пример распознавания текста
Будем считать что необходимые картинки для распознавания вы уже получили (отсканировали там, или скачали в интернете книгу в формате pdf/djvu и достали из них нужные картинки.
1) Открываем требуемую картинку в программе CuineForm (файл/открыть или «Cntrl+O«).
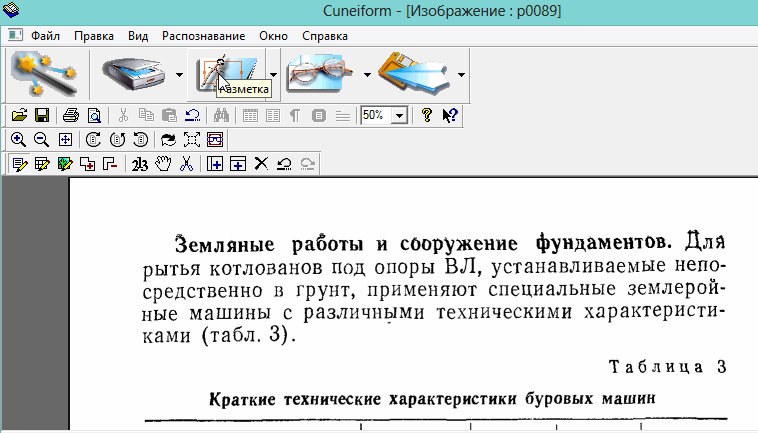
2) Чтобы приступить к распознаванию — нужно сначала выделить различные области: текста, картинок, таблиц и пр. В программе Cuneiform это можно сделать не только в ручную, но и автоматически! Для этого щелкните по кнопке «разметка» в верхней панели окна.
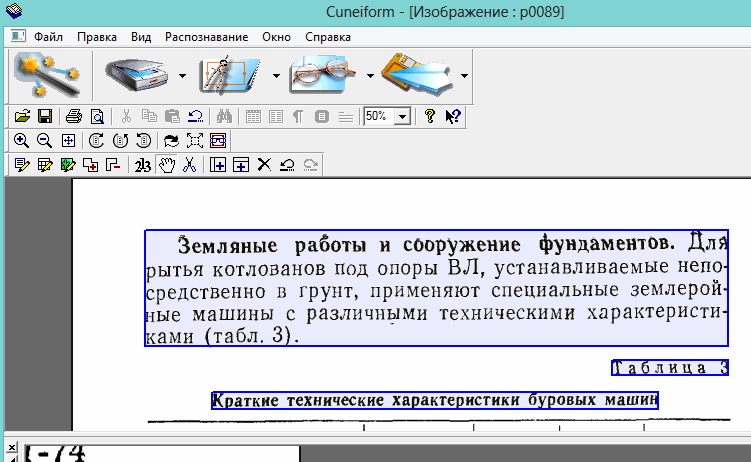
3) Спустя 10-15 сек. программа автоматически подсветит все области различными цветами. Например, область текста выделяется синим цветом. Кстати, подсветила она все области правильно и довольно быстро. Честно говоря, не ожидал от нее такой быстрой и правильной реакции…
4) Для тех, кто не доверяет автоматической разметке, можно воспользоваться и ручной. Для этого есть панелька инструментов (см. картинку ниже), благодаря которой можно выделить: текст, таблицу, картинку. Передвинуть, увеличить/уменьшить начальное изображение, подрезать края. В общем, неплохой набор.
5) После того, как все области были размечены, можно приступить к распознаванию. Для этого просто щелкните по одноименной кнопке, как на картинке ниже.
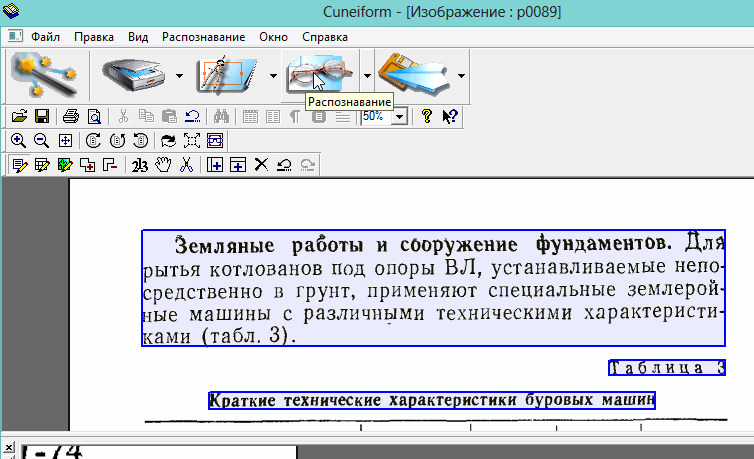
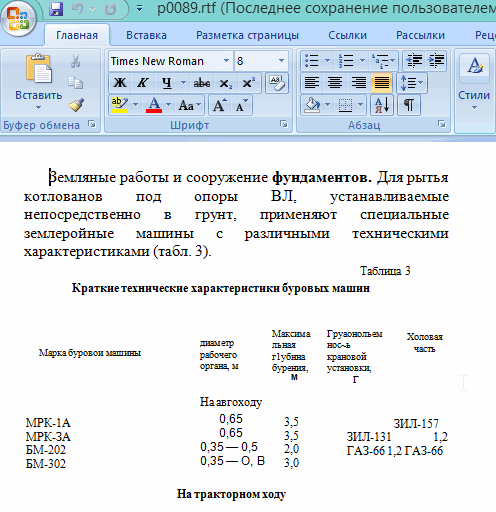
6) Буквально через 10-20 сек. перед вами откроется документ в Microsoft Word с распознанным текстом. Что интересно, в тексте для этого примера, ошибки, конечно были, но их крайне не много! Тем более, учитывая в каком невзрачном качестве был исходный материал — картинка.
По скорости и качеству вполне сравнимо с FineReader!
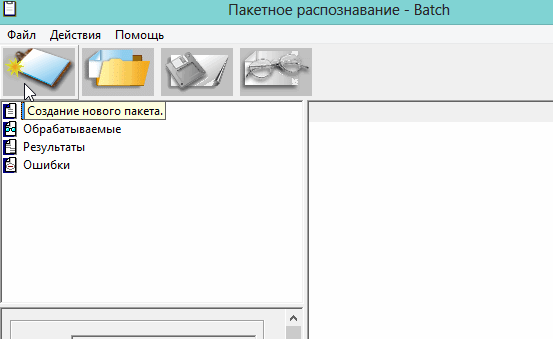
3. Пакетное распознавание текста
Эта функция программы может пригодится, когда вам нужно распознать не одну картинку, а сразу несколько. Ярлык для запуска пакетного распознавания, обычно, спрятан в меню «пуск«.
1) После открытия программы, вам нужно создать новый пакет, либо открыть ранее сохраненный. В нашем примере — создадим новый.
2) В следующем шаге даем ему название, желательно такое, чтобы и через полгода вспомнить что в нем сохранено.
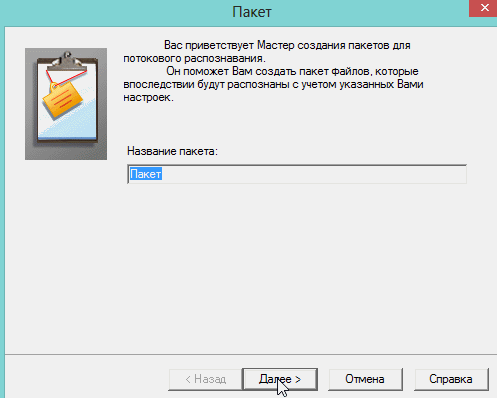
3) Далее выбираете язык документа (русско-английский), указываете, есть ли в вашем отсканированном материале картинки и таблицы.
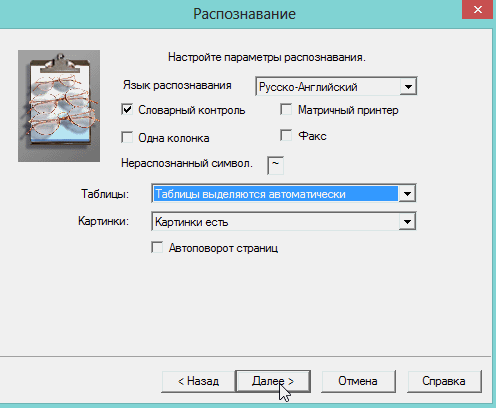
4) Теперь нужно указать папку, в которой расположены файлы для распознавания. Кстати, что интересно, программа сама найдет все картинки и другие графические файлы, которые она сможет распознать и добавить их в проект. Вам же останется удалить лишние.
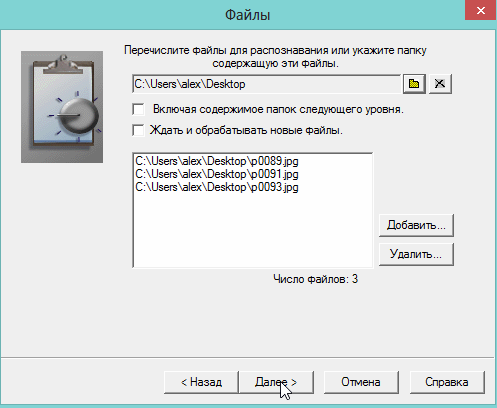
5) Следующий шаг не важен- выбираете что делать с исходными файлами, после распознавания. Рекомендую выбрать галочку «ничего не делать».
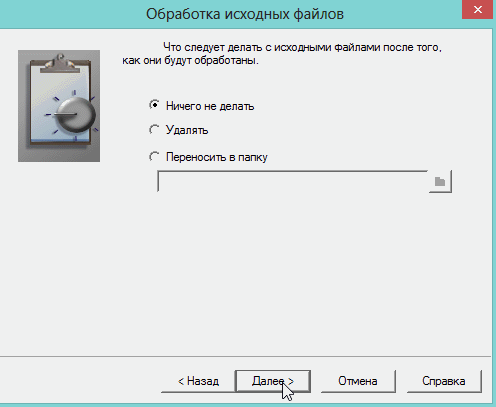
6) Осталось лишь выбрать формат, в котором будет сохранен распознанный документ. Есть несколько вариантов:
— rtf — файл из документа word, открывается всеми популярными офисами
— txt — текстовый формат, в нем можно сохранить только текст, картинки и таблицы нельзя;
— htm — гипертекстовая страничка, удобно, если вы сканируете и распознаете файлы для сайта. Его и выберем в нашем примере.
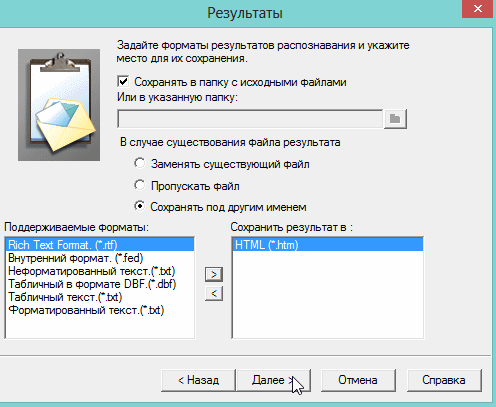
7) После нажатия кнопки «готово» запустится процесс обработки вашего проекта.
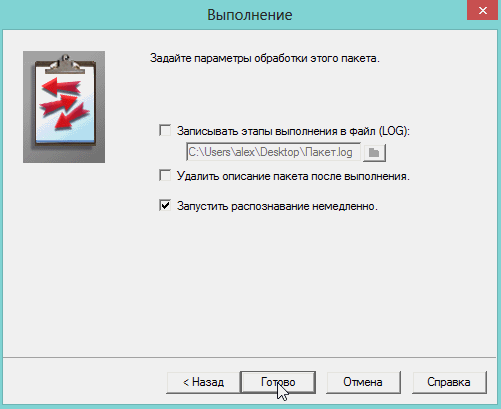
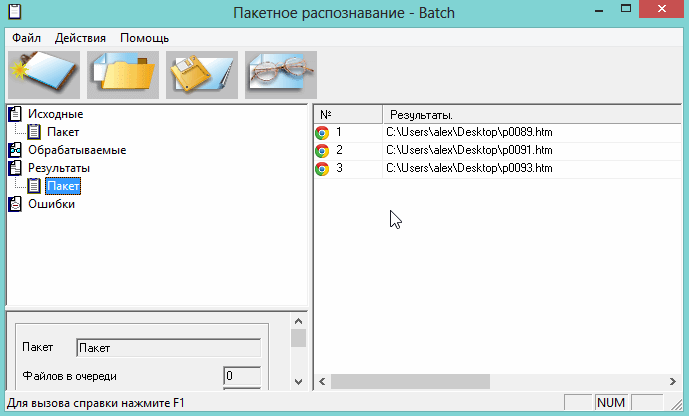
8) Программа работает довольно таки быстро. После распознания перед вами появится вкладка с файлами htm. Если щелкнуть по такому файлу запуститься браузер, где вы сможете увидеть результаты. Кстати, пакет можно сохранить для дальнейшей работы с ним.
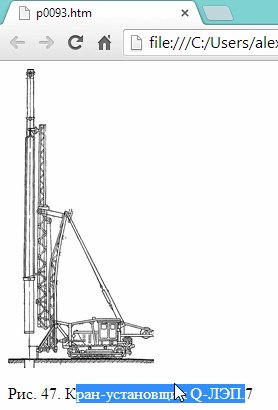
9) Как видно, результаты работы весьма впечатляющие. Картинку программа легко распознала, а под ней легко распознала текст. При том что программа и бесплатна — то вообще супер!

4. Выводы
Если вы часто не занимаетесь сканированием и распознаванием документов, то покупать программу FineReader, наверное, не имеет смысла. С большинством задач легко справляется CuneiForm.
С другой стороны, есть у нее и минусы.
Во-первых, слишком мало инструментов для редактирования и проверки получившегося результата. Во-вторых, когда приходится распознавать много картинок — то в FineReader удобнее сразу видеть в колонке справа всё, что добавлено в проект: быстро удалять лишнее, вносить правки пр. И третье, на документах совсем уж плохого качества, CuneiForm проигрывает в качестве распознавания: приходится документ доводить до ума — править шибки, проставлять знаки препинания, кавычки и т.д.
На этом все. А вы знаете какую-нибудь еще достойную бесплатную программу для распознавания текста?